The World of Graph Databases from An Industry Perspective
Published:
This paper by Yuanyuan Tian presents an overview of the graph database landscape from an industry perspective. It covers the graph database landscape, graph query languages and several graph database products. It also discusses the challenges and opportunities in the graph database industry.
Abstract
Rapidly growing social networks and other graph data have created a high demand for graph technologies in the market. A plethora of graph databases, systems, and solutions have emerged, as a result. On the other hand, graph has long been a well studied area in the database research community. Despite the numerous surveys on various graph research topics, there is a lack of survey on graph technologies from an industry perspective. The purpose of this paper is to provide the research community with an industrial perspective on the graph database landscape, so that graph researcher can better understand the industry trend and the challenges that the industry is facing, and work on solutions to help address these problems.
Graph Models
There are two prominent graph models supported by graph database products.
RDF
Resource description framework (RDF) is a World Wide Web Consortium (W3C) standard originally designed as a data model for metadata. It has come to be used as a general method for description and exchange of graph data. RDF provides a variety of syntax notations and data serialization formats, with Turtle (Terse RDF Triple Language) currently being the most widely used notation.
RDF is a directed graph composed of triple statements. An RDF graph statement is represented by: 1) a node for the subject, 2) an arc that goes from a subject to an object for the predicate, and 3) a node for the object. Each of the three parts of the statement can be identified by a uniform resource identifier (URI). An object can also be a literal value. This simple, flexible data model has a lot of expressive power to represent complex situations, relationships, and other things of interest, while also being appropriately abstract.
Property Graph
In contrast to the standard RDF, nodes in labelled property graphs have both IDs and a set of key-value pairs or attributes/properties. LPG edges/connections can have types and attributes (properties as the name suggests) natively, making the LPG data structure more dense, compact, and informative compared to RDF.
The rich internal structure of LPGs results in more efficient storage and faster data traversals and queries. At the same time, however, due to the arbitrary data structure design, LPGs are not as practical for modelling ontologies and other structured data representations as RDF models.
Property graphs are more popular to RDF in the industry even though, RDF is older and more mature. This is because a piece of information can only be represented either as a node or an edge in the RDF model, whereas the property graph model can also define it as an attribute of an existing node or edge, thus leading to fewer number of nodes and edges in the graph.
Graph Query languages
- The primary offering for RDF Graphs is SPARQL.
- For property graphs, there are two popular query languages: Cypher and Gremlin. Gremlin is widely supported by a lot of vendors while Cypher is only supported by Neo4j. Oracle proposed PGQL as a standard for property graph query language.
- GSQL is the SQL like query language for TigerGraph.
- Microsoft has the extended SQL framework with the MATCH clause for graph queries.
- The LDBC task-force is working on a standard graph query language called G-Core.
Gremlin is a more imperative language compared to all others. As a result, it is more low-level and less user-friendly. However, in terms of expressiveness, it is turing complete while other languages like Cypher are not. Out of the declarative languages, only GSQL, used by TigerGraph, is turing complete.
Graph Database Products
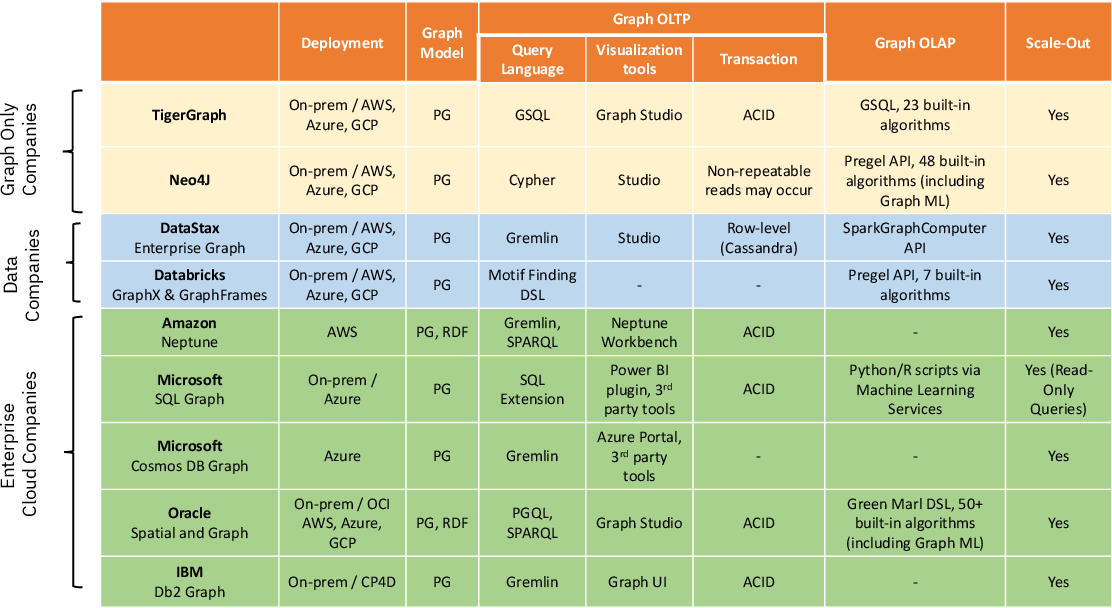
The above table shows the graph database products with their features. The table is taken from the paper.
Solution Space
Native vs Hybrid Graph Databases —— Native graph databases are designed from the ground up to support graph data. They are optimized for graph data storage and graph query processing. Neo4j and TigerGraph are examples of native graph databases. Hybrid graph databases are built on top of other database procudts. They use the underlying database to store the graph data and provide a graph layer on top of it. JanusGraph and CosmosDB are examples of hybrid graph databases.
Hybrid databases are faster to develop since they do not need a storage layer. However, they are not as performant as native graph databases.
Graph Only vs Multi-Model Graph Databases
Graph only databases are designed to store and process graph data only. Multi model databases support multiple data models. For example, CosmosDB supports key-value, document, columnar, and graph data models.
Multimodel graph databases solve the fragmented data problem by allowing application to work on heterogeneous data.
Graph Database Benchmarks
unline relational databases that have TPC-C, TPC-H and TP-CDS, there are no standard benchmarks for graph databases. LDBC benchmark is an effort to establish a standardised benchmark for graph databases. There are others like Linkbench from facebook, Graph500, HPC Scalable Graph Analytics Benchmark and Open Graph Benchmark for graph ML specifically.
Among these, LDBC is the most wodely accepted and adopted benchmark and hence closest to a standard for graph databases.